
JSONB Performance: What Developers Get Wrong
PostgreSQL’s JSONB type is incredibly powerful. It’s flexible, fast, and lets developers store semi-structured data without spinning up a separate document store. But here’s the truth: most JSONB performance problems come from treating JSONB like a magic box instead of a real data type with real indexing rules.
In this guide, I’ll show you how JSONB indexing works, how containment queries behave, and — maybe most importantly — when NOT to use JSONB at all using real examples from the Pagila Sample Database.
JSONB Is Fast — When You Use the Right Index
JSONB supports multiple index types, but most developers only ever create a GIN index and assume everything is covered. It isn’t. You need to match your index to the shape of your queries.
First, let’s add a JSONB column to the Pagila customer table and populate it:
ALTER TABLE customer
ADD COLUMN preferences JSONB;
UPDATE customer
SET preferences = jsonb_build_object(
'communication', jsonb_build_object(
'email_opt_in', (customer_id = 1),
'sms_opt_in', (customer_id % 3 = 0)
)
);
This gives us a predictable JSON structure for each customer: communication → email_opt_in → true/false. Only one row has true, which makes the query highly selective — perfect for the screenshot demonstrations I'll show you below.
Now run a containment query before adding any index:
EXPLAIN ANALYZE
SELECT customer_id, first_name, last_name
FROM customer
WHERE preferences @> '{"communication": {"email_opt_in": true}}';
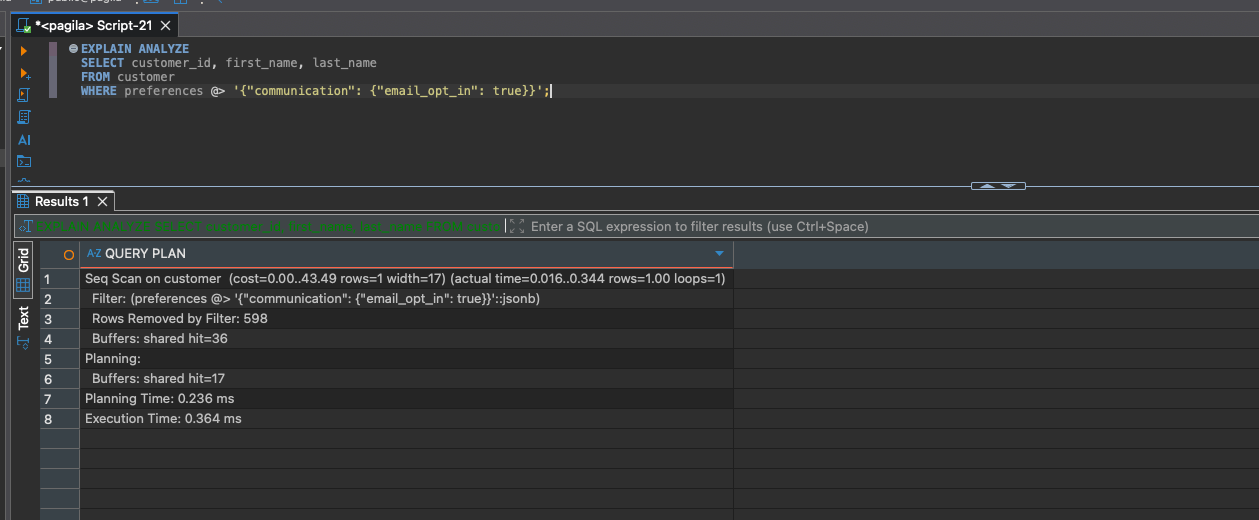
You’ll see a Seq Scan. PostgreSQL must inspect every JSON document and check whether it contains the JSON on the right side. That’s how containment works: the JSON on the left must be a superset of the JSON on the right.
Now let’s add a GIN index:
CREATE INDEX idx_customer_prefs_gin
ON customer USING GIN (preferences);
Run the same query again:
EXPLAIN ANALYZE
SELECT customer_id, first_name, last_name
FROM customer
WHERE preferences @> '{"communication": {"email_opt_in": true}}';
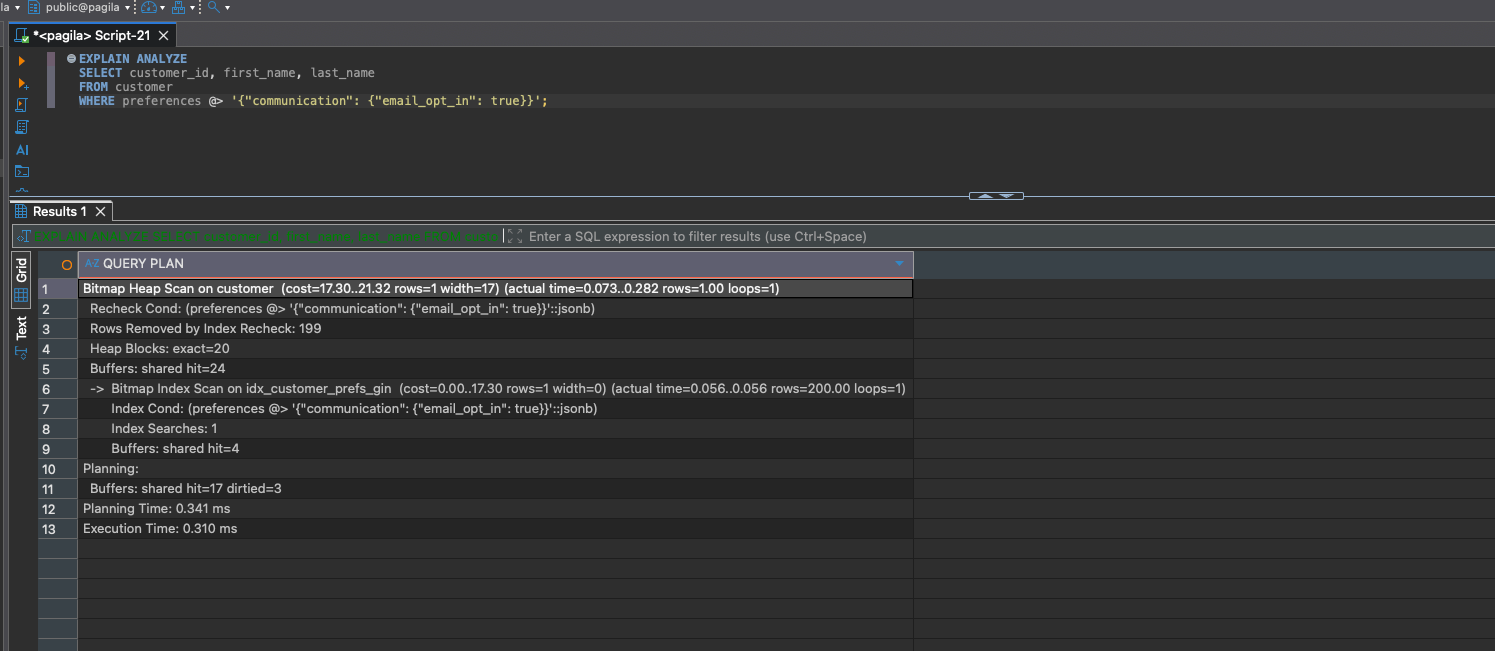
This time you should see a Bitmap Index Scan using idx_customer_prefs_gin. GIN indexes are perfect for containment queries (@>) because they index the keys and values inside the JSON document.
Now let’s look at a totally different type of JSONB query — extracting a specific key and checking equality. This is not containment. This is a simple value comparison.
Run this equality query before adding a BTREE index:
EXPLAIN ANALYZE
SELECT customer_id
FROM customer
WHERE (preferences->'communication'->>'email_opt_in') = 'true';
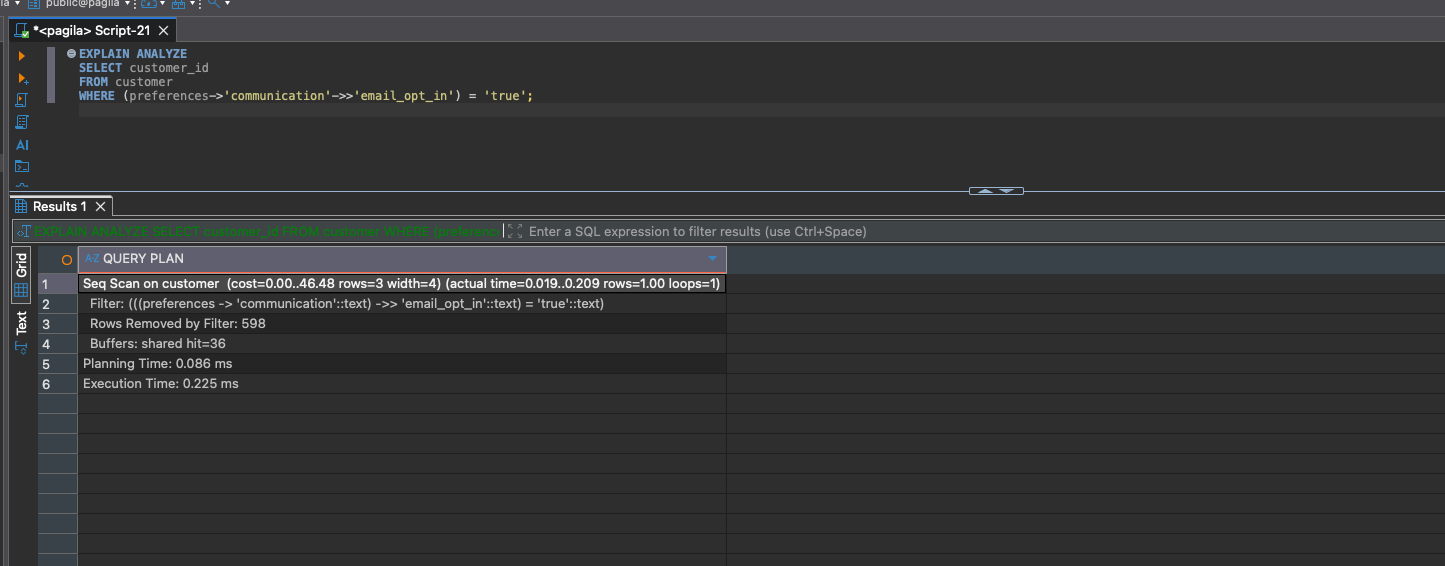
PostgreSQL will do a Seq Scan again. Even though only one row matches, PostgreSQL has no index to optimize this specific comparison.
Now add a BTREE expression index:
CREATE INDEX idx_customer_email_opt_in
ON customer ((preferences->'communication'->>'email_opt_in'));
Run the equality query again:
EXPLAIN ANALYZE
SELECT customer_id
FROM customer
WHERE (preferences->'communication'->>'email_opt_in') = 'true';
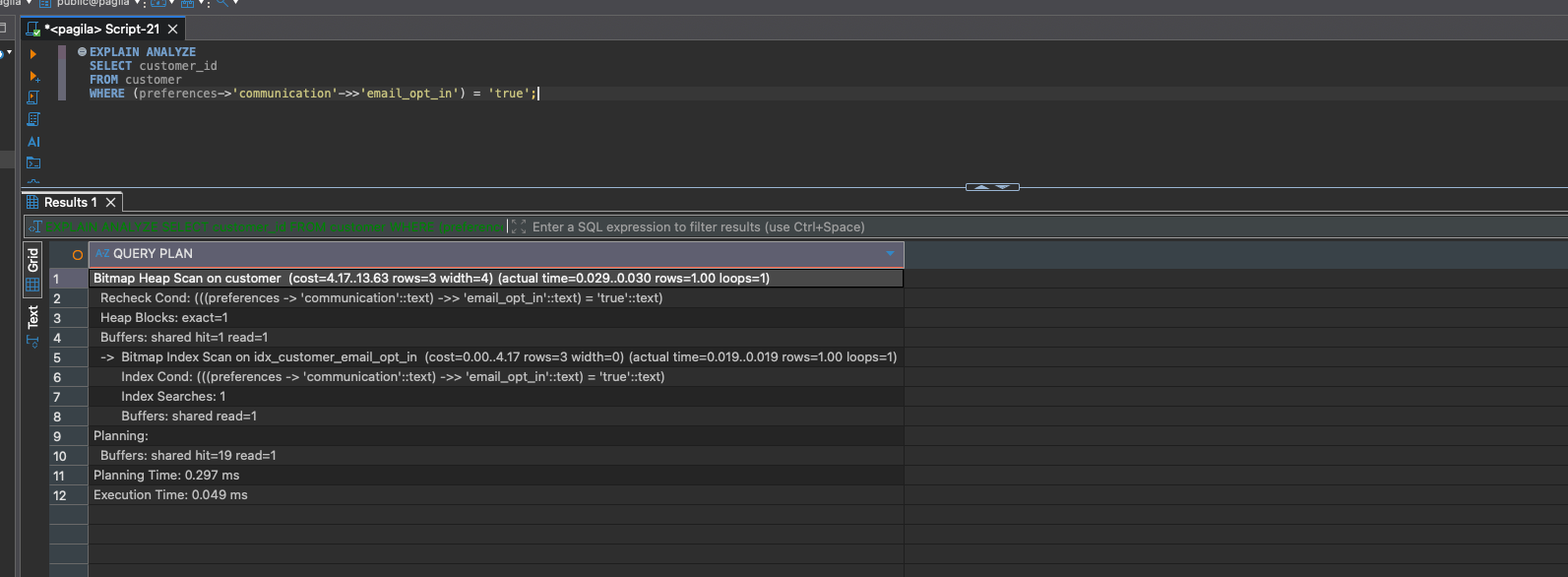
Now PostgreSQL uses a Bitmap Index Scan on idx_customer_email_opt_in. BTREE expression indexes are perfect for equality checks on extracted JSON values.
The rule of thumb here is simple:
Use GIN for document search, and BTREE for targeted key lookups.
Containment Queries: The Most Misunderstood Feature
JSONB containment (@>) isn’t magic — it’s just a structural comparison. PostgreSQL checks whether every key and value on the right side appears in the left side. Because it’s comparing JSON structures — not simple values — containment can be expensive unless indexed properly.
SELECT customer_id
FROM customer
WHERE preferences @> '{"communication": {"sms_opt_in": true}}';
This matches rows even when the JSON document has extra fields, because containment only checks whether the right-hand JSON is a subset of the left. But keep in mind: if many rows match, PostgreSQL may use a sequential scan instead of the GIN index, since containment can be expensive on non-selective data.
The #1 JSONB Anti-Pattern: Storing Relational Data in JSONB
JSONB is fantastic for optional, sparse, or flexible fields. It is terrible for structured relational values. Avoid JSONB when the data:
- is filtered frequently
- needs to be sorted
- participates in joins
- requires constraints (unique, foreign key, not null)
Think about Pagila’s actor table. If someone suggested moving first_name and last_name into JSONB, the right response is: Absolutely not.
JSONB gives flexibility at the cost of structure. If the structure matters, keep it relational.
When JSONB Is Actually the Right Tool
You should reach for JSONB when:
- Different rows need different sets of attributes
- You’re storing configuration blobs
- You’re persisting API payloads
- You rarely query inside the JSON itself
You should not use JSONB when:
- You know the schema ahead of time
- The values will be filtered, sorted, or joined
- You need strict constraints
- Performance needs to be predictable
Performance Tips Most Developers Miss
- Create indexes that match query patterns.
- Normalize what should be relational.
- Avoid deep nesting.
- Be cautious with large arrays.
- Consider jsonb_path_ops for containment-heavy workloads.
Conclusion
JSONB is one of PostgreSQL’s most impressive features — but only when used with care. If you choose the right indexes, design predictable JSON structures, and avoid shoving relational data into documents, you’ll get excellent performance without surprises.
Use JSONB where it shines, normalize what matters, and your PostgreSQL database will stay fast, flexible, and easy to tune even as your application grows!





